Musi
X
Plateforme de gestion musicale
Cette plateforme permet de venir scraper les metadonnées depuis les API des plateformes de streaming audio (Spotify, Deezer...) ainsi que les artistes et playlists du moment tout en les intégrant au sein de fichier audio en flac.
Introduction
Sujet & Objectifs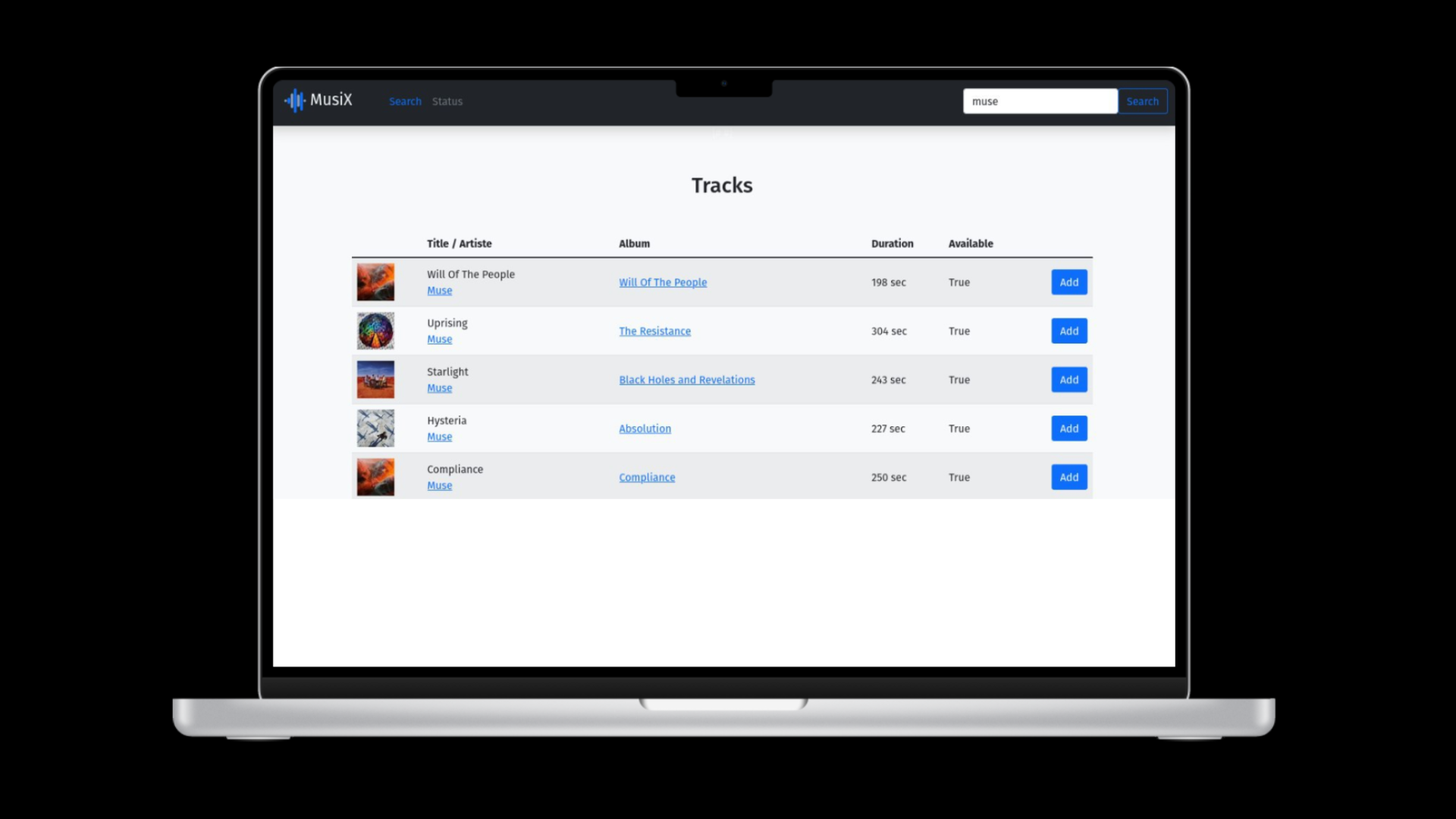
Dans le cadre de mon semestre à Troyes à l’UTT, j’ai souhaité pouvoir faire un projet étudiant me permettant de découvrir et d’approfondir des technologies web tout en alliant mes passions pour la Hifi et la musique avec le développement de plateforme web.
Étude et réalisation d’une API de gestion de bibliothèque musicale ainsi que de gestion d’utilisateur, avec téléchargement automatique de musique libre de droit.
Les objectifs de ce projet était la conception de modules de gestion de bibliothèque musicale, de gestion de compte utilisateurs, de téléchargement de musique. Dans un second temps je souhaite avoir la possibilité d’effectuer une veille relative aux langages de programmation et technologies permettant de réaliser des applications web ainsi que les types de base de données et ORM et pour terminer j’ai conteneurisé le projet et mise en production.
Recherche langage de programmation
adapté au projet
J’ai tout d’abord débuté le projet en me posant la question du langage de programmation le plus à même de répondre au sujet.
Pour cela, j’ai retenu 3 solutions :
La première solution basée sur du JS était intéressante mais d’après mes recherches moins optimisé que du Rust et moins rapide à développer que du Python. J’ai donc retenu la solution en RUST pour l’API et la solution basé sur Python avec Django pour la partie front et pour le worker Deezer.
Le langage de programmation RUST à été conçu et développé par Mozilla Research depuis 2010. Il s’agit d’un langage compilé lui conférant des performances en vitesse d’exécution supérieures à celles des langages interprétés. La gestion de la mémoire est exigeante mais très efficace, car RUST n’utilise pas de garbage collector. RUST vérifie l’ensemble du code, de telle sorte que tout dépassement de mémoire est impossible. Cela implique certes beaucoup de rigueur dans le développement en RUST, mais en contrepartie engendre une précision et une performance accrues sur le code en sortie.


Il existe de nombreux framework fonctionnant avec Rust tel que warp, gotham.rs, Iron.rs et Actix.rs qui sont très bien en termes de fonctionnalités et de rapidité. Par contre, ils sont plus complexes à prendre en main en l’absence de documentation adaptée pour les débutants et liés au nombre important de fonctionnalités intégrés. J’ai donc choisi Rocket.rs car il est facile à prendre en main et répond aux fonctionnalités nécessaires à cet application.
Python est un langage de programmation bien plus ancien que Rust dont la première version est sortie en 1991, il à été créé par Guido van Rossum. Il s’agit d’un langage puissant, simple en termes de syntaxe et très riche en termes de possibilité.Il s’agit d’un langage de programmation interprété, ce qui signifie que les instructions du programme sont transcrites au fur et à mesure de la lecture en langage machine ce qui va rendre ce type de programme moins rapide à l'exécution. Cependant, avec la puissance de calcul des ordinateurs de nos jours, cette différence d'exécution tend de plus en plus à être transparente pour l’utilisateur.


Django est un framework web open-source particulièrement répandu dans la programmation en Python et qui permet de développer des applications web en Python de haut niveau offrant ainsi la possibilité d'accélérer la création d’applications web.Django embarque avec lui de nombreuses applications tierces ou bien bibliothèques qui peuvent être intégrées en fonction des exigences du projet.On peut par exemple citer le framework Django REST ou bien Django CMS ou bien encore Django-allauth.Cependant Django dispose tout de même de certains inconvénients. En effet, il n'est pas particulièrement intéressant à utiliser pour des projets de petite taille. On pourrait plutôt dans ce cas la s’orienter vers flask. De même, il n'est pas possible d'intégrer de websocket avec Django qui aurait permis de faire une application temps réelle. Pour cela nous aurions dû nous tourner vers un framework tel que aiohttp.
Recherche type & driver
de base de donnée
Qu’est ce qu’un ORM?
ORM signifie Object-Relational Mapping. Comme illustré dans la figure 1 ci-dessous, il s'agit d’un ensemble de classes permettant de manipuler les tables d’une base de données relationnelle comme s’il s’agissait d’objets. C’est donc une couche d’abstraction d’accès à la base de données qui donne l’illusion de ne plus travailler avec des requêtes de type SQL par exemple mais de manipuler des objets. Le principal avantage de cette couche d’abstraction et qui en fait son point fort est qu’il n’y a plus besoin de se soucier du système de base de données utilisé, c’est l’ORM qui a la charge de transformer les requêtes pour les rendre compatibles avec la base de données. Il est donc possible de passer d’une base de donnée PostgreSQL à une base de donnée MySQL ou bien MongoDB sans aucun changement dans le code de l’application. La seule modification à faire sera de changer le type de base de donnée en sortie afin que L’ORM traduise dans un langage compréhensible par la nouvelle base de donnée les instructions précédemment codées.
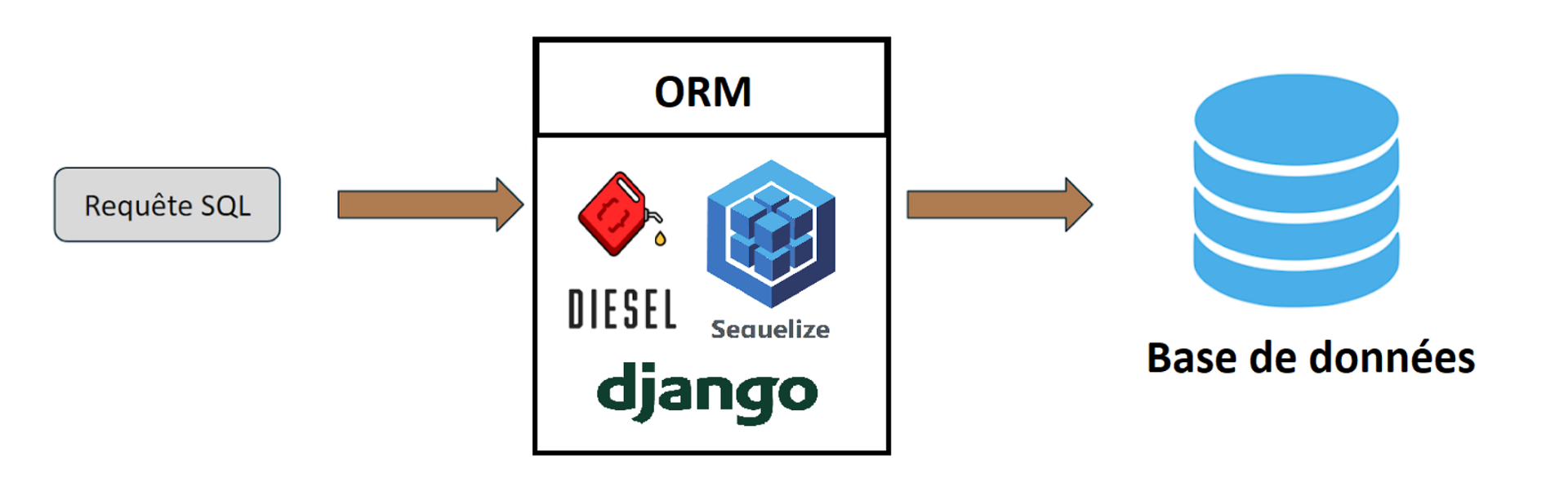
Il existe de nombreux types de bases de données ayant chacune des emplois particuliers.
Tout d’abord les bases de données relationnelles comme Oracle, MySQL ou bien PostgreSQL.
Ce type de base de données stocke les ensembles de données de manière « relationnelle » comme son nom l’indique. C'est-à-dire qu’elles mettent en relation les données. Cela se concrétise par l’organisation de données en tables. Les systèmes de BDD relationnelles utilisent dans leur majorité le langage SQL. De plus, ils sont réputés pour leur cohérence et leur fiabilité.
Ce type de base de données à de nombreuses forces notamment le fait qu’il soit très puissant pour stocker et manipuler des données très structurées, les données sont stockées facilement et peuvent être extraites très simplement à l’aide de requêtes SQL et finalement elles sont scalables, ainsi l’augmentation du volume de données stocké n’a pas d’incidence sur les données existantes et l’organisation de la base de données.
Cependant ce qui fait leur force fait aussi leur faiblesse, c’est-à-dire qu’elles sont mal adaptées à la gestion de données non-structurées. De plus, la normalisation très importante des données stockées dans la BDD a tendance à générer des structures de données complexes, fragmentées et difficiles à faire évoluer ce qui implique qu’elles soient plus coûteuses à mettre en place, à faire évoluer et à maintenir.
D’un autre côté nous avons les bases de données orientées documents tel que MongoDB précédemment évoqué. Il s’agit de bases de données non relationnelles qui vont stocker les données sous forme de documents dans des formats tels que le JSON, le XML ou bien encore le BSON. Ce type de bases de données ne supporte pas les schémas de données prédéfinis. Ainsi elles sont d'avantages flexibles par rapport à une base de données relationnelle. En effet, contrairement aux bases SQL, où les utilisateurs doivent définir un schéma de tableaux avant de charger les données, les documents de stockage n’ont pas de structure fixe et figée. La structure s’adapte au contenu. De ce fait, les documents peuvent contenir n’importe quels types de données. Les données sont enregistrées et organisées dans des collections, qui jouent le rôle des tableaux SQL cependant avec des champs d’enregistrement libres. De par l’utilisation de paires clé-valeur et de méta-données d’attributs les requêtes sont facilitées.
Nous retrouvons aussi les bases de données orientées clé valeur tel que Memcache. Il s’agit d’un type de base de données non relationnelle où chaque valeur est associée à une clé spécifique. C’est le type le plus simple de base NoSQL. Une clé est un identifiant unique associé à une seule valeur. Les clés peuvent se présenter sous toutes les formes permises par le système de gestion utilisé.
Il existe encore bien d’autres types de bases de données tels que les bases de données orientés colonnes tel que Big Table ou bien les moteurs de recherche tel que Elasticsearch cependant elles n'étaient pas particulièrement intéressantes dans notre cas d’utilisation car nous n’avons que des données à stocker qui sont essentiellement des données structurées.
API
Après une étude complète des possibilités que ce soit en terme de technologies de développements liés aux langage de programmation que sont JS, Python ou bien Rust ainsi que les framework respectivement associés qui sont express avec sequelize, django ou bien rocket avec diesel, je me suis orienté vers la solution composé du combo Rust, Rocket et PostgreSQL qui à donc pour objectif de permettre la gestion d’une bibliothèque musicale, ainsi que d’utilisateurs et des logs permettant de retracer les interactions des utilisateurs avec la plateforme.
Nous avons dû faire le choix du langage de développement et du framework utilisés pour l’API du serveur destiné à gérer la bibliothèque musicale, l'authentification, la gestion et le stockage des interactions des utilisateurs sur l’application.
Il existe certes de nombreux frameworks permettant de réaliser des API, nous avons décidé de nous diriger vers RUST et Rocket car il s’agit d’un langage particulièrement optimisé du fait de son bas niveau compilé tout en présentant certains avantages des langages haut niveau. Par ailleurs, contrairement à ses homologues, il présente de meilleures performances et une gestion de la mémoire bien supérieure.
Tout d’abord je me suis orienté vers une base de donnée relationnelle car étant donné le type d’informations à stocker c'était l’architecture de base la plus intéressante et adaptée.
Les principales options que nous avions étaient MySQL, PostgreSQL et Sqlite étant donné que notre ORM n’est capable de gérer que ces trois bases.
Je me suis directement orienté vers MySQL et PostgreSQL et ai mis de côté Sqlite car ce type de base de données aurait certes pu être intéressant dans le cadre du développement du projet cependant il est vraiment destiné à une utilisation pour un projet de petite taille. Ce qui potentiellement pourrait poser problème par la suite étant donné la quantité de musique ajoutée tous les jours.
Je me suis donc intéressé aux deux autres options possibles et les ai comparées afin de voir laquelle des deux pouvait être la plus adéquate.
Nous avons donc d’un coté PostgreSQL qui est plus fiable et l’intégrité des données y est plus performante, elle dispose d’un planificateur ainsi qu’un optimiseur de requêtes et est meilleure pour les requêtes avec sous-requêtes et enfin, propose une licence MIT qui est plus permissive que la licence GPL de MySQL.
D’un autre côté, MySQL est plus adapté pour les applications en lecture seule telles que des applications web. En ce sens, MySQL fonctionne bien avec PHP et propulse beaucoup d’outils web. MySQL est très répandu et peut s’utiliser sans effort de configuration et est plus rapide sur des requêtes simples par rapport à PostgreSQL.
J’ai préféré opter pour PostgreSQL et les avantages cités ci dessus qui correspondaient d'avantages aux attentes du sujet.
Plateforme musicale
Réalisation d’une maquette du frontde l’application avec Figma

Afin de pouvoir avoir une idée claire du look de l'application ainsi que des éléments à y faire figurer je me suis orienté vers la conception d’une maquette sous figma. J’ai choisi les couleurs puis les différentes zones et réparti puis positionner les composants nécessaires à l’utilisation de l’application par l’utilisateur comme on peut le voir dans la figure 2.
J’ai par la suite réalisé un logo pour l’application( voir rendu en figure 2). Pour cela je me suis inspiré des ondes sonores et de la retranscription des signaux sonores en signal électrique.
Je l’ai exporté au format SVG car il à pour particularité de permettre de ne perdre aucune qualité quelque soit le zoom étant donné que l’on se trouve sur des formes primaires réalisés via des vecteurs. De plus ce format est tout particulièrement intéressant et simple à mettre en place pour du web via du html et CSS.
Ce projet à donc été réalisé avec le langage de programmation Python et via le framework Django. Il repose sur l’utilisation de l’API de Deezer, qui permet de récupérer les informations des tracks tels que les noms des artistes, albums, date de créations tracks constituants les albums ou bien les tops artistes, albums, tracks ou playlist du moment. Cette application permet aux utilisateurs de trouver n’importe quelle musique présente sur Deezer et de recueillir ses informations. Afin de réaliser le front de l’application, j’ai utilisé le moteur de template Jinja2 qui est intégré dans Django et qui permet de réaliser des pages statiques avec des éléments dynamiques qui sont rendus via l’app django.
Pour mettre en place le formulaire de recherche que ce soit pour les titres, artistes ou bien album, je me suis orienté vers la lib django crispy form qui permet de styliser les formulaires sur django et notamment avec bootstrap. J’ai choisi de m’orienter vers le framework CSS Bootstrap car il est simple à utiliser et je le trouve moderne et intuitif pour les utilisateurs. En effet j'ai comparé à certains autres notamment Bulma qui était un concurrent sérieux cependant la patte et le style graphique des composants me plaisait moins.
Dockerisation & containerisation
du projet
Qu'est ce qu’un conteneur & la conteneurisation ?
La conteneurisation consiste à rassembler le code de l’application ainsi que tous ses composants de manière à les isoler dans un conteneur avec l’ensemble des éléments dont elle a besoin pour fonctionner. L'application dans le conteneur peut ainsi être déplacée et exécutée de façon cohérente dans tous les environnements et sur toutes les infrastructures, indépendamment de leur système d'exploitation (windows, mac ou linux). En effet, avec les conteneurs, il n'est plus utile de développer pour une plateforme ou un système d'exploitation en particulier.
Il existe différentes technologies de conteneurisation telles que podman, LXC ou bien Docker.
Docker est majoritairement utilisé et déployé par les entreprises du fait des avantages qu’il propose tel que sa « légèreté » ou bien la portabilité des conteneurs qui découle de leur capacité à partager le noyau du système d'exploitation de la machine hôte. Ils n'ont pas besoin d'un système d'exploitation propre et les applications peuvent s'exécuter de la même manière sur toutes les infrastructures (systèmes bare metal, clouds et même machines virtuelles). De plus Docker permet via kubernetes ou bien docker Swarm de mettre en place des systèmes de Load Balancing et de HA rendant ces système très résilients et intéressants pour une utilisation de serveur d’API.
De la même manière un container LXC est un processus ou un ensemble de processus isolés du reste du système. Tous les fichiers nécessaires à leur exécution sont fournis par une image distincte, ce qui signifie que les conteneurs Linux sont portables et fonctionnent de la même manière dans les environnements de développement, de test et de production. Ainsi, ils sont bien plus rapides à utiliser que les pipelines de développement qui s'appuient sur la réplication d'environnements de test traditionnels. En raison de leur popularité et de leur facilité d'utilisation, les conteneurs constituent également un élément essentiel de la sécurité informatique.
Dans le cadre de ce projet qui avait pour vocation de découvrir de nouvelles technologies j’ai mis en place la containerisation de ce projet sous deux technologies de containerisation différentes. Pour la partie API elle à été mise en place avec docker et pour la partie downloader et front elle à été réalisé avec un container LXC.
Afin de mettre en place les containers LXC pour le programme python je me suis tourné vers la distribution proxmox qui est tout à fait adaptée à ce type d'utilisation.
Pour la partie docker, j’ai rencontré de nombreuses difficultés à dockeriser le projet car j'utilisais des bibliothèques Rust qui n'étaient pas stables mais en mode nightly qui est incompatible avec la mise en production. J’ai été obligé de forcer la création du container pour que cela fonctionne cependant cette solution n’est pas viable pour faire évoluer le projet par la suite. Je me suis donc rendu compte qu’il était très important de bien choisir les bibliothèques et framework adaptées à certains projets.
Mise en production du projet
Choix entre auto hébergement ou locationd’un serveur en datacenter
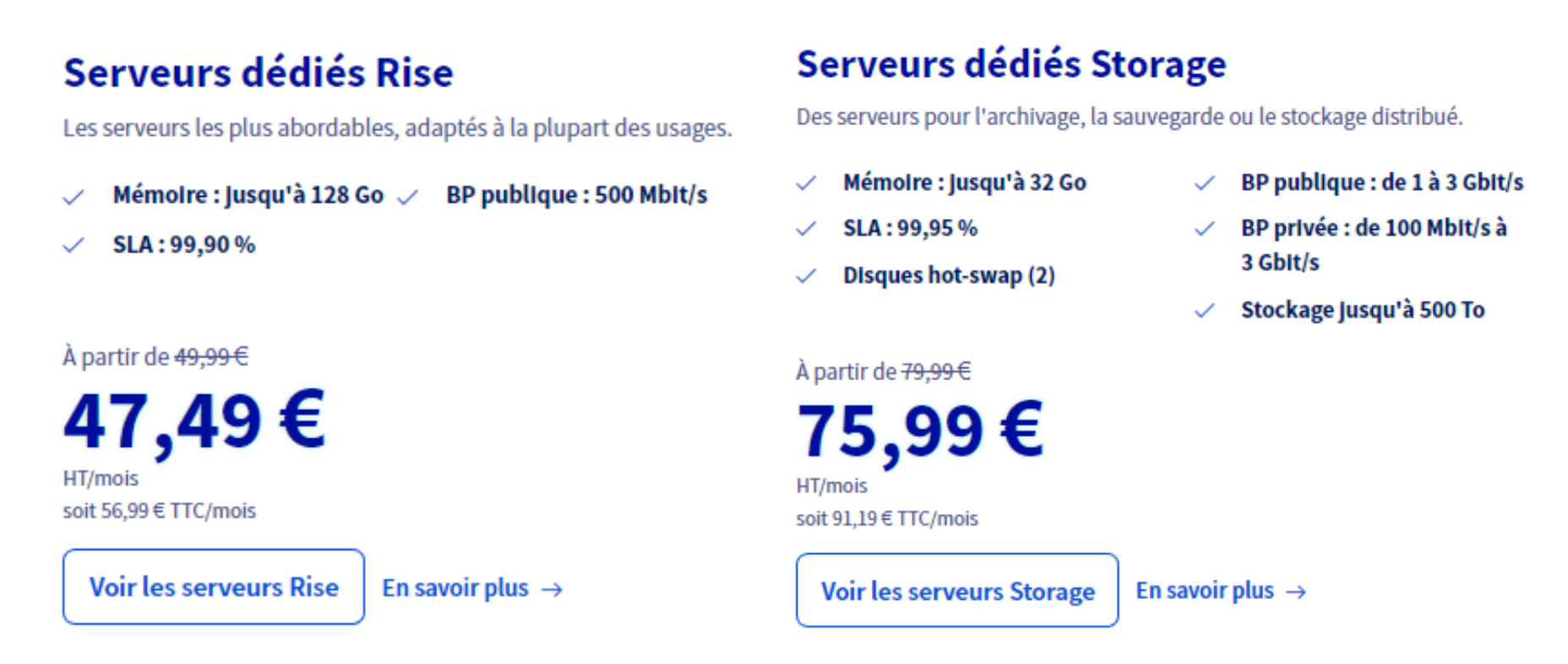
Comme on peut le voir sur la figure 4 ci dessus le tarif au mois de ce type de serveur est plutôt élevé, je me suis donc orienté vers de l’auto hébergé qui à bien sûr des inconvénients tel que la facture électrique importante, les désagréments dû à la chauffe, le bruit ainsi qu’un uptime qui est moins bon que pour un serveur en DC mais qui coûte bien moins chère à l’année et pour lesquels on n’aura pas de surprise de coût supplémentaires liés à la bande passante ou au stockage en cas de bug.

Afin de rendre accessible ce service depuis l'extérieur j’ai mis en place une architecture de serveur auto hébergé permettant de répondre à cet objectif.
Pour cela j’ai mis en place 2 serveurs :
Pour le premier serveur j’ai mis en place un Proxmox installé bare metal qui est une solution permettant de faire de la virtualisation que ce soit pour des machine virtuelles ou bien des containers.


Pour le second serveur j’utilise la distribution Unraid qui me permet de réaliser des points de montage accessible depuis le serveur proxmox et via les containers afin de pouvoir stocker les données directement via une liaison 10gb/s sur le serveur de stockage.
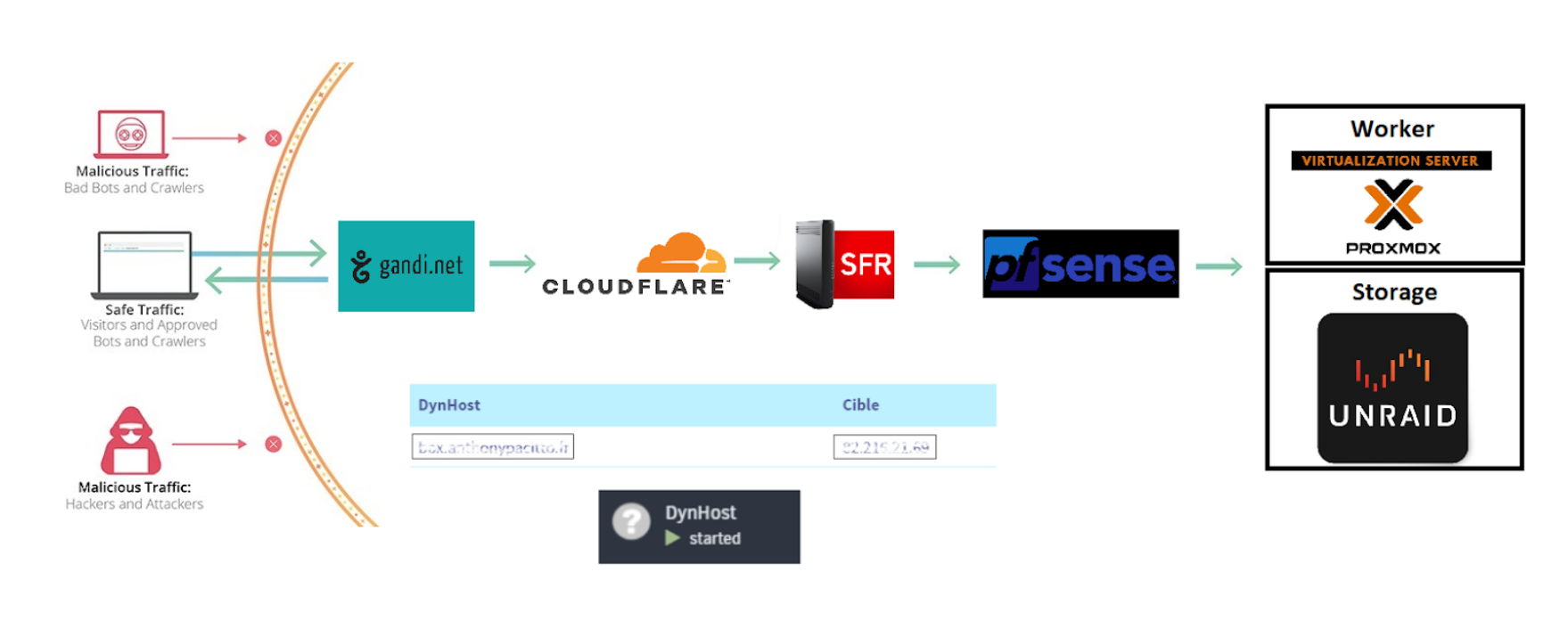
L’objectif étant de la rendre accessible depuis l'extérieur, tout le monde pourrait y avoir accès. Comme on peut l’observer sur la figure 6, afin d’atteindre l’objectif de mise en production, il va falloir mettre en place plusieurs services tel qu’un reverse proxy permettant de rendre disponible la ressource via un nom de domaine. Pour cela nous allons utiliser nginx pour le reverse proxy et gandi pour le nom de domaine. etant donné que mon FAI (fournisseur d’accès internet(SFR dans mon cas) ne me permet pas d’avoir une adresse IPV4 full stack statique, je dois utiliser un service qui me permet de mettre à jour l’adresse IPV4 de ma box lié à mon nom de domaine tel que DynDNS. Ensuite il est préférable de passer par un proxy tel que celui de cloudflare afin de sécuriser l’accès à ses ressources du DDOS ou bien d’utilisateur malveillant. Cela permet en plus de protéger mon IPV4 de ma box qui est par conséquent non visible par les utilisateurs étant donné qu'elle se trouve derrière le proxy de Cloudflare.
Enfin via des services tels que fail2ban qui permet de limiter l’accès au ressources géographiquement ou bien pour certaines IP connu de bots et d'utilisateurs avec des comportements anormaux cela permet de sécuriser davantage notre système.
Conclusion
Ce projet m’a permis de découvrir et de pratiquer une démarche de développement dans le cadre d’un projet alliant musique et programmation qui sont mes deux passions.
De plus, j'ai beaucoup appris quant aux méthodes permettant de nous mener à la résolution de problèmes techniques, que ce soit au niveau des termes de recherche à utiliser ou bien des réflexes à avoir pour traiter certains types d’erreurs qui n'étaient pas des automatismes pour moi.
Ce projet m’a permis de découvrir, redécouvrir et de me perfectionner sur plusieurs technologies, notamment les API Rest que ce soit dans le langage RUST, JS ou bien Python complétant mes connaissances et compétences transversales dans les différents domaines travaillés. J’ai pu développer mes capacités d’apprentissage en autonomie notamment pour la prise en main de nouvelles technologies et le travail en mode projet.
J’ai également pu mettre à profit les connaissances acquises précédemment durant mon cursus pour réaliser les projets confiés et notamment les matières EG23 pour la conception et le maquettage d’interface, la réalisation de logo ou bien grâce à LO07 la mise en place de base de données et du requêtage SQL.
J’ai aussi pu me rendre compte de l’importance du choix des framework davantage orientés vers certaines utilisations ainsi que de l’importance de bien lire les documentations afin de pouvoir davantage anticiper certaines problématiques liés au bibliotheques encore en phase de bêta et qui peuvent changer du jour au lendemain et par conséquent remettre en cause la totalité du projet.
Ce projet à été particulièrement formateur, même si il n’à pas pu être terminé étant donné la quantité de travail à fournir que j’ai mal dimensionné pour tenir en 1 semestre cependant cela à du bon car j’ai pu me rendre compte de mes limites et de ma capacité à prendre en mains de nouvelles technologies.